

Solutions to Repeated Output Issues with Whisper
Recently, there have been numerous reports in Memo feedback regarding the issue of repeated outputs during audio transcription. The feedback is as follows:
- "Transcription frequently encounters this issue... repeatedly transcribing the same sentence..."
- "The video is eight and a half minutes long, but from about the 4-minute mark, it keeps repeating until the end."
- "The bug where it gets stuck repeating a single sentence during recognition seems to be getting worse. Some files that used to be transcribed normally can't be transcribed properly anymore."
- "The large zh model cannot transcribe long videos. After a few minutes, it starts repeating and gets stuck. My GPU has 8GB of memory."
- "Do you have the issue of a subtitle repeatedly transcribing the same sentence?"
Common Operations
Based on the feedback, I've summarized a few situations where hallucination and repetition issues frequently occur. However, please note that due to differences in audio quality and device performance, there is no one-size-fits-all solution.
Using the Large-v3 Model for Transcription
The Large-v3 model tends to encounter more issues compared to Large-v2 and Large-v1. You might wonder, what's the difference between these models? In reality, there isn't a significant difference; the primary distinction is that Large-v3 supports Cantonese transcription.
Recommended Solution: Switch to a different model for transcription.
Transcribing Chinese or Minor Language Content
Whisper's Chinese corpus is definitely less extensive than its English corpus. Whisper utilizes a method where it uses previous transcription results to prompt the current transcription. Therefore, if it can't recognize something clearly, it starts to make things up based on previous results.
Recommended Solution: Use a Chinese model for transcription or try other models one by one.
Long Meeting Recordings, Movies, or Audio with Mixed Sounds
Given the way Whisper's inference works, if an audio segment has too many mixed sounds, the probability of transcription failure increases.
Recommended Solution: Use third-party tools to process the audio. You can search "voice extraction" on Google to find the appropriate tools.
Insufficient Device Performance
The core issue is that the model inference requires resources, and lack of them causes hallucinations.
Recommended Solution: In transcription advanced settings, enable voice activity detection, switch models, or use a machine with better performance.
Incorrect Language Selection (English Video Transcribed as Chinese)
If the video is in English, don't select Chinese for transcription. AI inference will eventually cause hallucinations if the language isn't matched correctly.
Recommended Solution: Select the corresponding language for transcription and then translate it in the subtitle page.
Memo AI Solutions
Many might ask, "How does Memo AI solve this hallucination and repetition issue?" To be honest, it's challenging because enterprise-level services usually run on stable, high-performance servers, which have a much lower probability of encountering issues than local devices. The configuration parameters and system versions of users' devices vary greatly, making standardization difficult. However, we have tried some solutions.
Prompts
Here are some prompts I tested that might be effective:
ignore the background sound of the music and only transcribe the part with the human voice.ignore noise, white space, musical background sounds, and transcribe the part that speaks.This is a meeting, transcribe the voice of the conversation in the meeting and ignore the noiseRefer to the image below for usage.
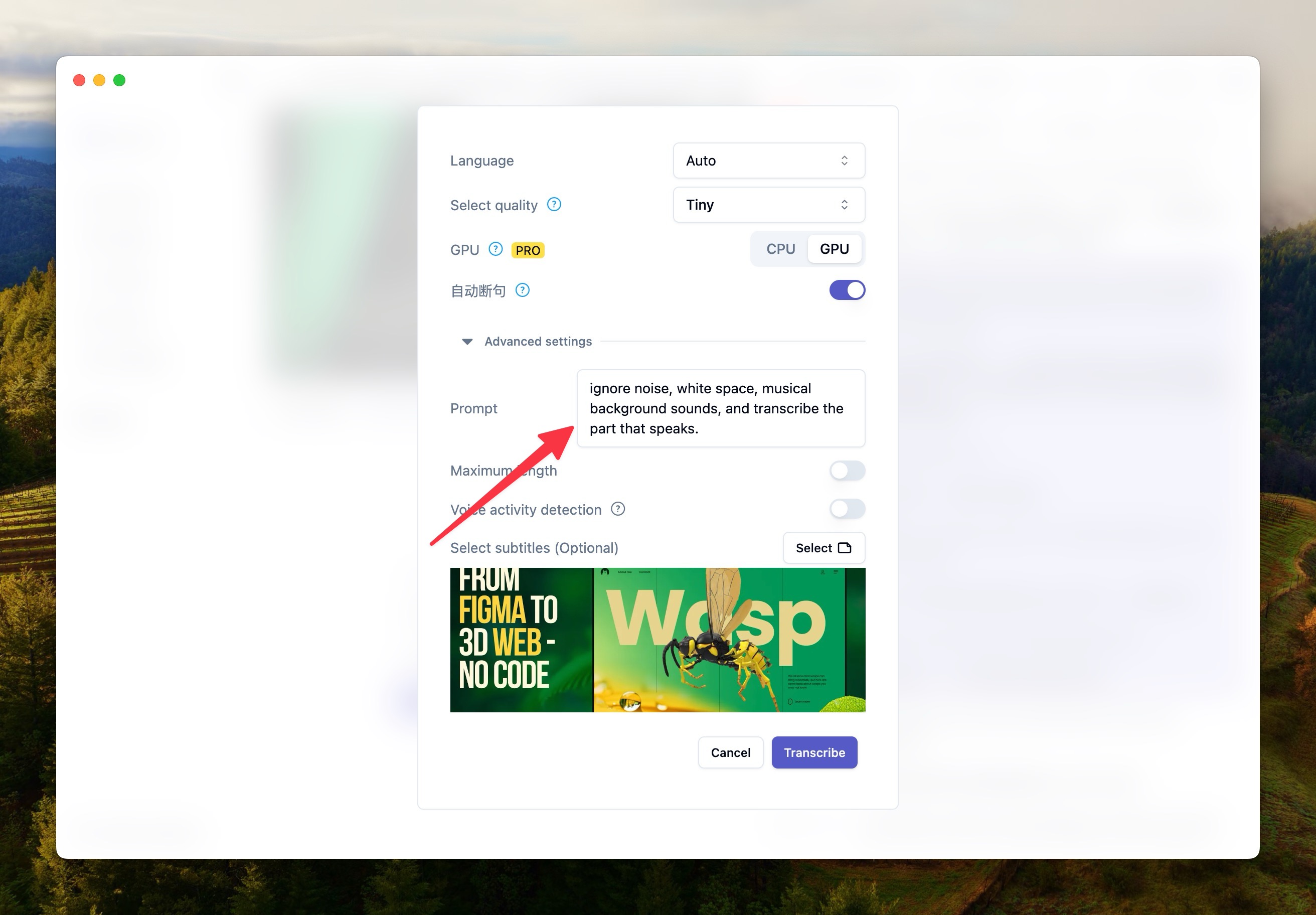
Voice Activity Detection
If the hallucination is caused by blank time segments, combining language activity detection should relatively easily solve it. Refer to the image below to enable voice activity detection in the advanced settings during transcription.
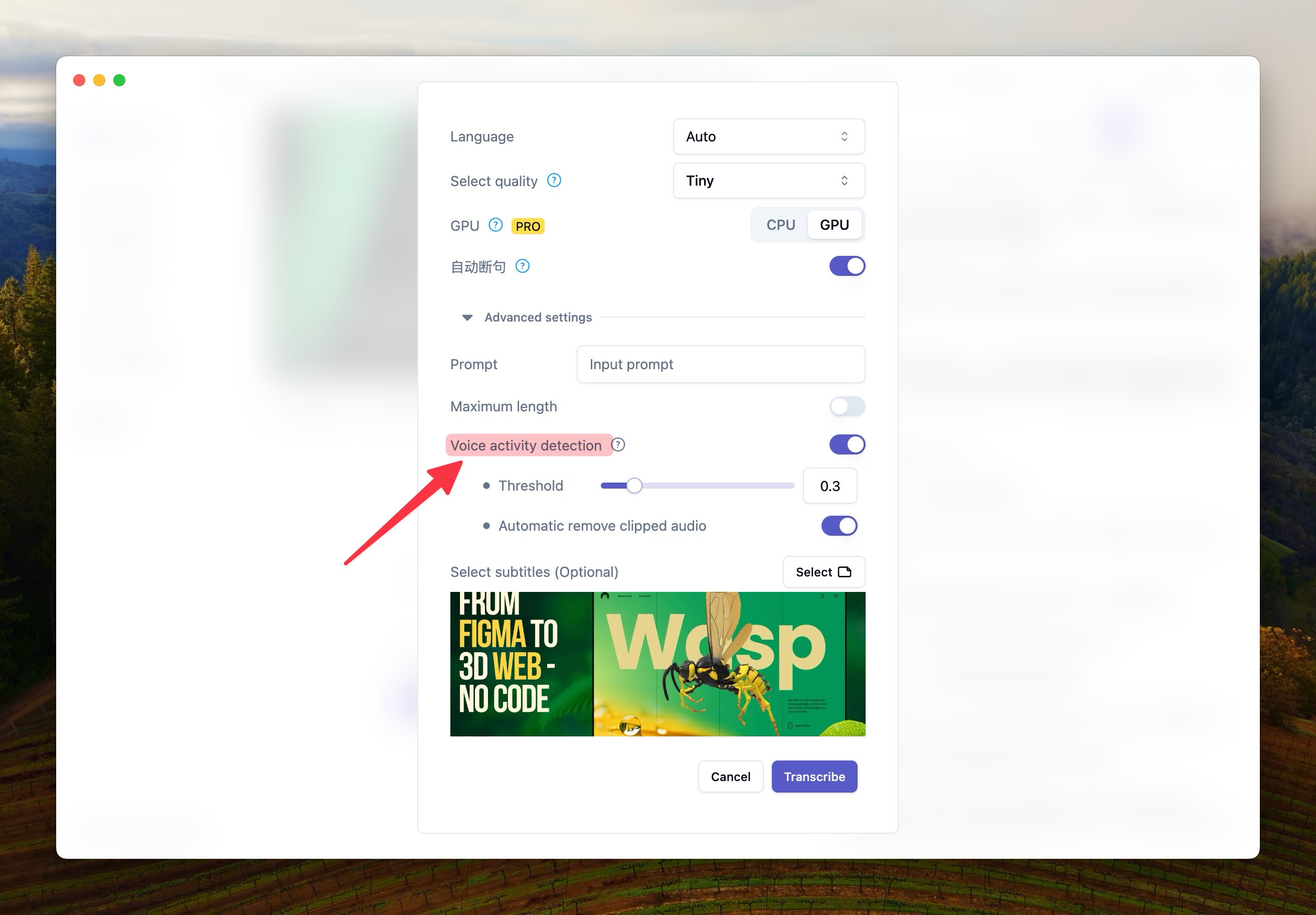
However, voice detection can also have some minor issues, such as missing some voiced parts or still causing hallucinations in noisy background segments.
Segment Transcription
For parts with hallucinations, you can right-click, select, and re-transcribe the specific parts that need transcription.
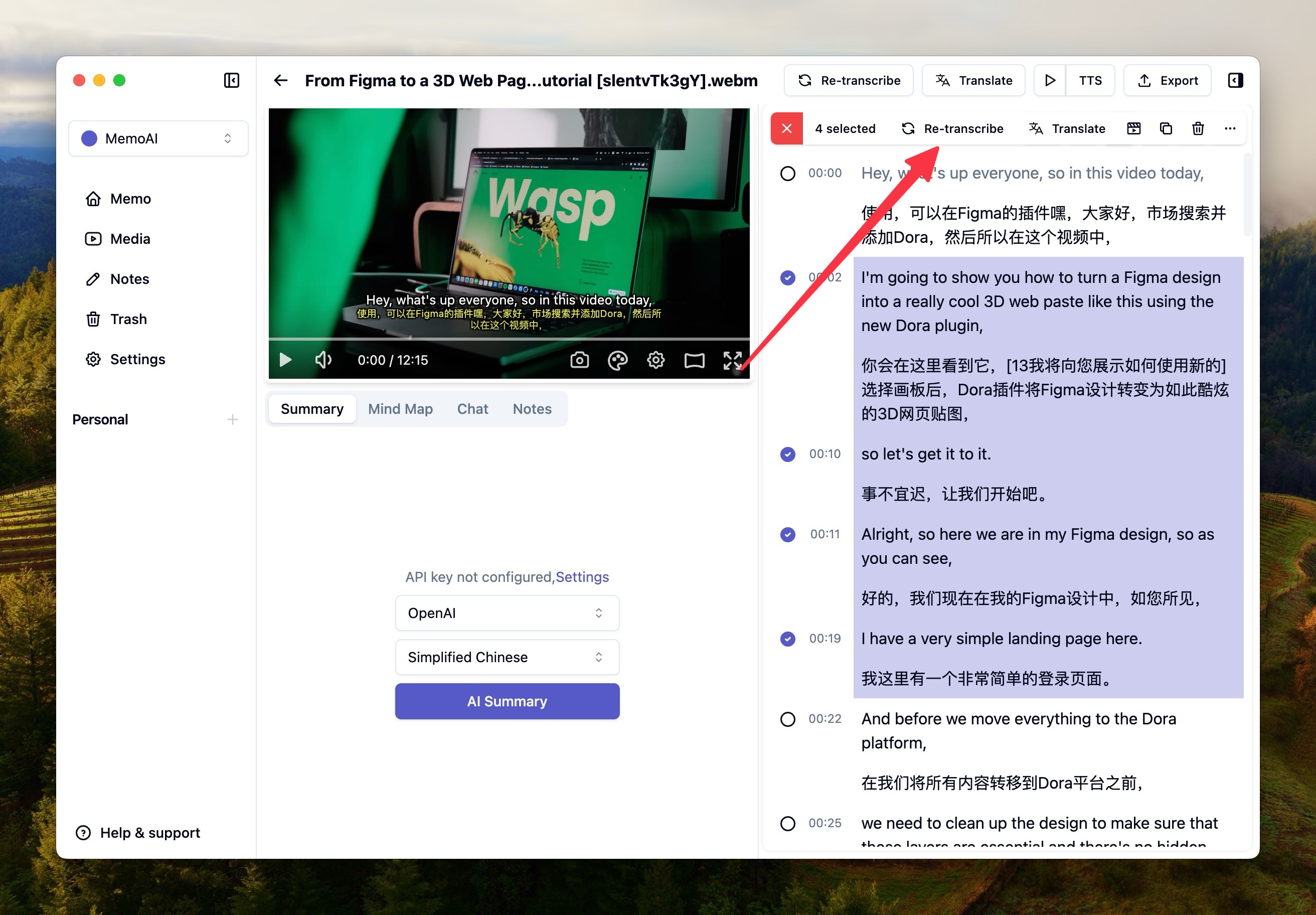
Voice Separation
This is the ideal method. However, our research shows that voice separation methods are relatively time-consuming. For some devices with lower performance, separating an hour-long video might take an hour, which is not friendly to local transcription speeds.