

Whisper 輸出重複問題解決方案
最近 Memo 的反饋中,有許多關於轉寫音頻出現重複輸出的問題。反饋內容如下:
- "轉寫經常遇到這個問題...瘋狂重複一句話..."
- "影片八分半,從四分鐘左右就一直在重複,直到結束。"
- "識別的時候卡在一句話一直重複,這個 bug 好像現在越來越嚴重了。一些以前能正常轉寫的,現在重新轉寫都不行了。"
- "large zh 無法轉錄長視頻,幾分鐘之後就會不斷重複卡死,顯存 8G。"
- "請問一下,你們會有識別一句話字幕一直重複的 bug 嗎?"
常見操作
根據反饋,我總結了以下幾種情況會經常發生幻覺重複問題,但請注意:由於音頻品質和設備性能有差異,無法提供統一標準答案。
使用 Large-v3 模型轉寫
Large-v3 模型出現問題的概率遠高於 Large-v2 和 Large-v1。當然有人會問,這三者有什麼區別?實際上沒有太大區別,最大的區別就是 Large-v3 支援粵語轉寫。
推薦方案: 更換模型重新轉寫。
轉寫中文或小語種內容
Whisper 的中文語料明顯少於英文語料。Whisper 採用了一種利用前序轉錄結果來提示當前轉錄結果的方法,因此如果無法正確識別內容,就會開始依賴前序結果胡編亂造。
推薦方案: 更換中文模型轉寫,或者逐個嘗試其他模型。
會議長段空白、電影或混雜音頻
基於 Whisper 的推理方式,如果音頻中混雜的聲音太多,轉寫失敗的概率也會增加。
推薦方案: 使用第三方工具對音頻進行處理,可以谷歌搜尋「人聲提取」來獲取相應的工具。
設備性能不足
核心問題在於模型推理需要的資源不足,導致幻覺。
推薦方案: 在轉寫高級設置中打開語音檢測,切換模型或更換性能更好的機器。
選錯語言,將英文視頻轉寫成中文
如果是英文視頻,不要選擇中文。AI 推理到一定程度就會出現幻覺。
推薦方案: 根據音頻實際語言選擇相應語言轉寫,然後進入字幕頁面,點擊右上角進行翻譯。
Memo AI 解決方案
很多人會問,Memo AI 如何解決這種幻覺重複問題?坦白說很難,因為企業級服務本來運行在穩定高性能的伺服器中,出問題的概率遠低於本機設備。每個人的設備配置參數、系統版本都不統一,很難做到標準化。但我們也嘗試了一些方案。
提示詞
以下是我測試可能有效的提示詞:
ignore the background sound of the music and only transcribe the part with the human voice.ignore noise, white space, musical background sounds, and transcribe the part that speaks.This is a meeting, transcribe the voice of the conversation in the meeting and ignore the noise具體使用請參考下圖。
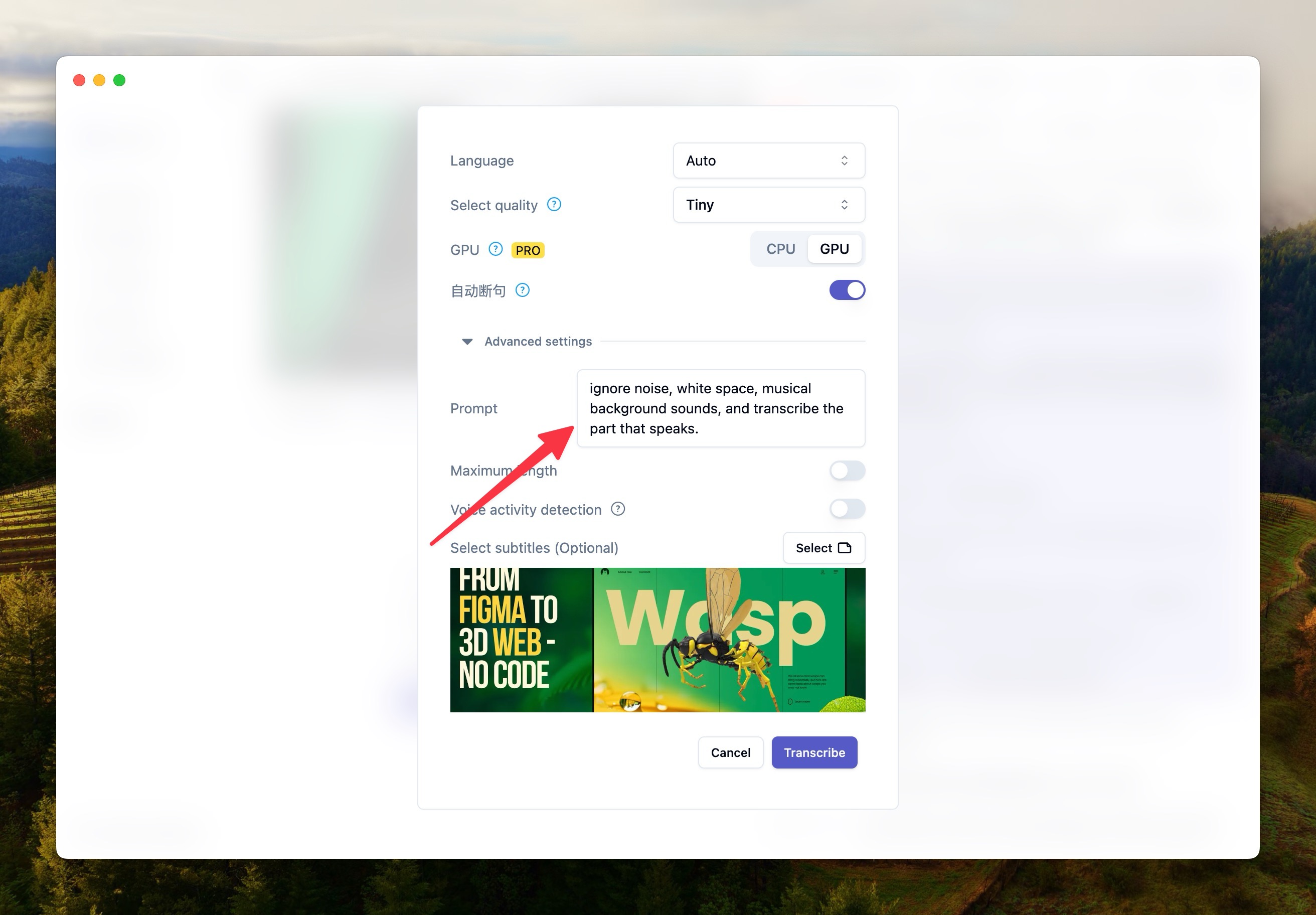
語音檢測
如果幻覺是由於空白時間段導致的,配合語言活動檢測應該相對容易解決。參考下圖轉寫過程中,在高級設置中啟用語音檢測。
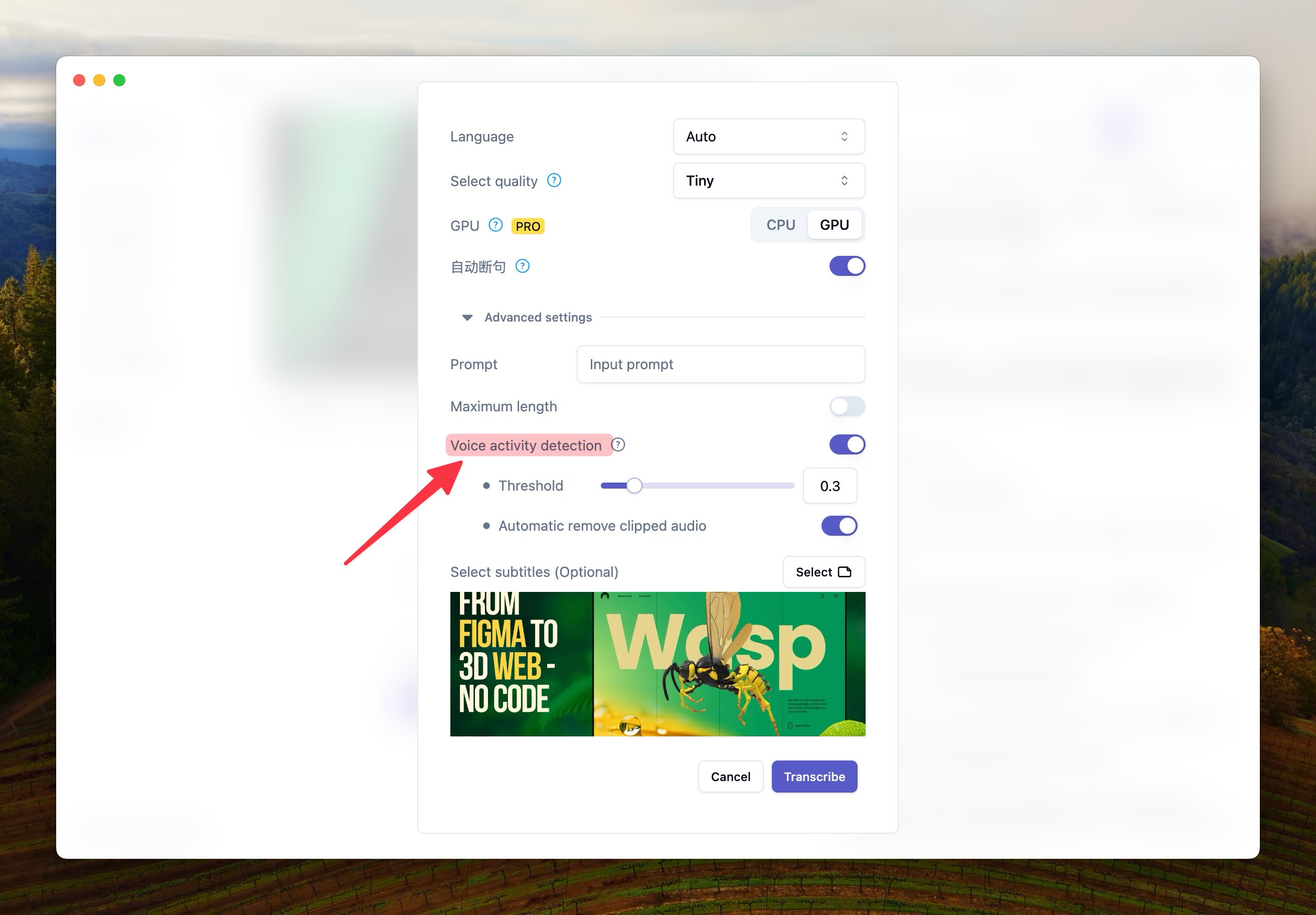
語音檢測也會有一些小問題,例如部分有聲部分可能會被錯漏,背景音嘈雜的部分仍然會出現幻覺。
區域轉寫
對於部分有幻覺的地方,可以通過右鍵選擇並勾選需要轉寫的部分重新轉寫。
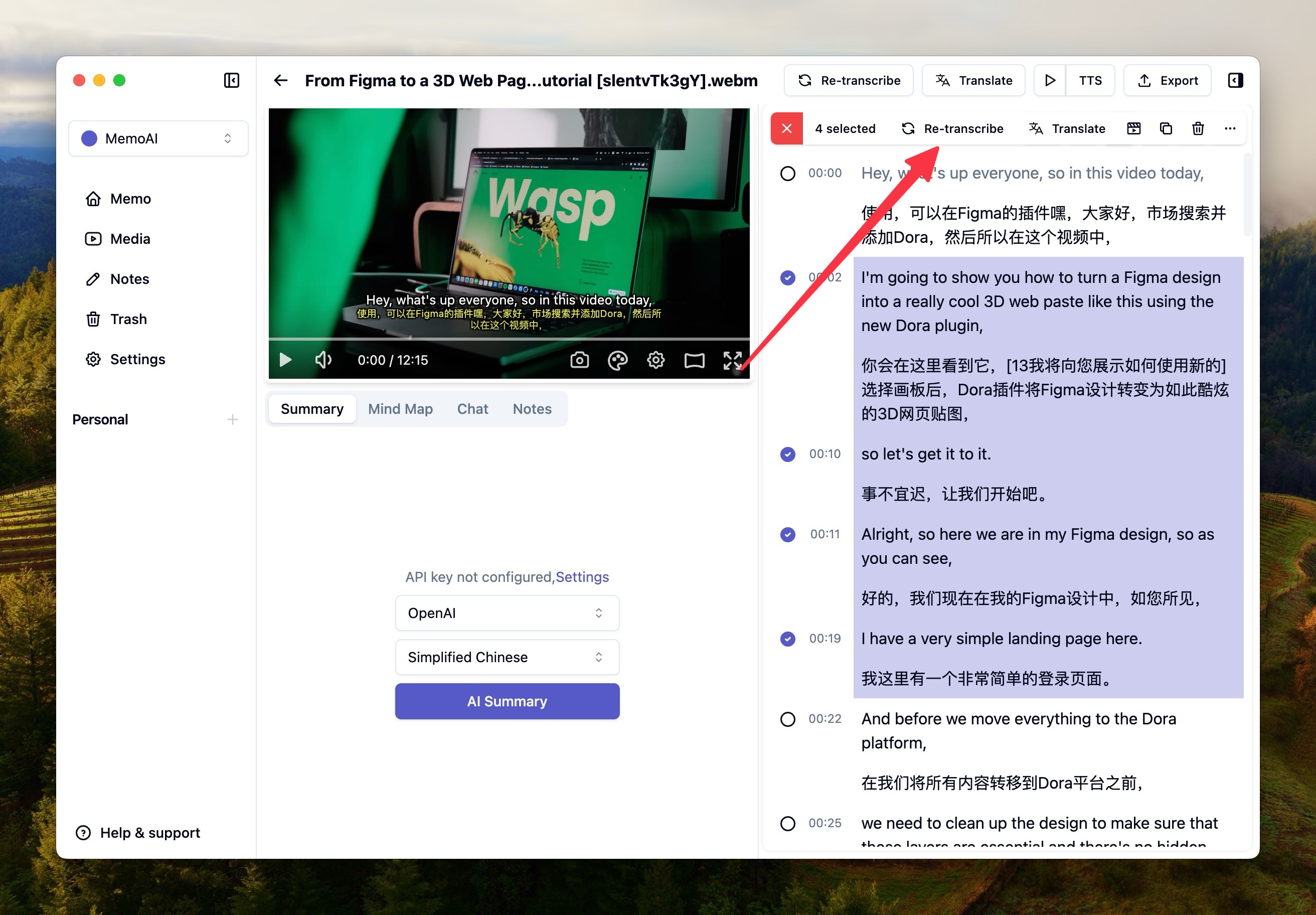
人聲分離
這是最理想的方式,但我們調研發現,人聲分離方式相對耗時,部分低性能設備分離一小時的視頻需要一小時,這對於本地轉寫速度並不友好。